Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 3 of 3 results drugs clear search

A simple computational algorithm for simulating population substance use
Jacob Borodovsky | Published Thursday, March 27, 2025This code simulates individual-level, longitudinal substance use patterns that can be used to understand how cross-sectional U-shaped distributions of population substance use emerge. Each independent computational object transitions between two states: using a substance (State 1), or not using a substance (State 2). The simulation has two core components. Component 1: each object is assigned a unique risk factor transition probability and unique protective factor transition probability. Component 2: each object’s current decision to use or not use the substance is influenced by the object’s history of decisions (i.e., “path dependence”).
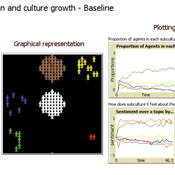
Evolutionary Model of Subculture Choice
Diogo Alves | Published Monday, December 19, 2022This is an original model of (sub)culture diffusion.
It features a set of agents (dubbed “partygoers”) organized initially in clusters, having properties such as age and a chromosome of opinions about 6 different topics. The partygoers interact with a set of cultures (also having a set of opinions subsuming those of its members), in the sense of refractory or unhappy members of each setting about to find a new culture and trading information encoded in the genetic string (originally encoded as -1, 0, and 1, resp. a negative, neutral, and positive opinion about each of the 6 traits/aspects, e.g. the use of recreational drugs). There are 5 subcultures that both influence (through the aforementioned genetic operations of mutation and recombination of chromosomes simulating exchange of opinions) and are influenced by its members (since a group is a weighted average of the opinions and actions of its constituents). The objective of this feedback loop is to investigate under which conditions certain subculture sizes emerge, but the model is open to many other kinds of explorations as well.
Agent-based model of risk behavior in adolescence
N Schuhmacher P Van Geert L Ballato | Published Monday, June 24, 2013 | Last modified Monday, April 08, 2019The computer model simulates the development of a social network (i.e. formation of friendships and cliques), the (dyadic) interactions between pupils and the development of similarities and differences in their behavioral profiles.