Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1195 results for "Aad Kessler" clear search
Evolutionary Dynamics of the Warring States Period: Initial Unification in Ancient China (475 BC to 221 BC)
zhuo zhang | Published Sunday, August 07, 2022If you have any questions about the model run, please send me an email and I will respond as soon as possible.
Under complex system perspectives, we build the multi-agent system to back-calculate this unification process of the Warring State period, from 32 states in 475 BC to 1 state (Qin) in 221 BC.
Open Peer Review Model
Federico Bianchi | Published Monday, May 24, 2021This is an agent-based model of a population of scientists alternatively authoring or reviewing manuscripts submitted to a scholarly journal for peer review. Peer-review evaluation can be either ‘confidential’, i.e. the identity of authors and reviewers is not disclosed, or ‘open’, i.e. authors’ identity is disclosed to reviewers. The quality of the submitted manuscripts vary according to their authors’ resources, which vary according to the number of publications. Reviewers can assess the assigned manuscript’s quality either reliably of unreliably according to varying behavioural assumptions, i.e. direct/indirect reciprocation of past outcome as authors, or deference towards higher-status authors.
Peer reviewed BAMERS: Macroeconomic effect of extortion
Alejandro Platas López Alejandro Guerra-Hernández | Published Monday, March 23, 2020 | Last modified Sunday, July 26, 2020Inspired by the European project called GLODERS that thoroughly analyzed the dynamics of extortive systems, Bottom-up Adaptive Macroeconomics with Extortion (BAMERS) is a model to study the effect of extortion on macroeconomic aggregates through simulation. This methodology is adequate to cope with the scarce data associated to the hidden nature of extortion, which difficults analytical approaches. As a first approximation, a generic economy with healthy macroeconomics signals is modeled and validated, i.e., moderate inflation, as well as a reasonable unemployment rate are warranteed. Such economy is used to study the effect of extortion in such signals. It is worth mentioning that, as far as is known, there is no work that analyzes the effects of extortion on macroeconomic indicators from an agent-based perspective. Our results show that there is significant effects on some macroeconomics indicators, in particular, propensity to consume has a direct linear relationship with extortion, indicating that people become poorer, which impacts both the Gini Index and inflation. The GDP shows a marked contraction with the slightest presence of extortion in the economic system.
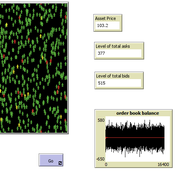
Peer reviewed A financial market with zero intelligence agents
edgarkp | Published Wednesday, March 27, 2024The model’s aim is to represent the price dynamics under very simple market conditions, given the values adopted by the user for the model parameters. We suppose the market of a financial asset contains agents on the hypothesis they have zero-intelligence. In each period, a certain amount of agents are randomly selected to participate to the market. Each of these agents decides, in a equiprobable way, between proposing to make a transaction (talk = 1) or not (talk = 0). Again in an equiprobable way, each participating agent decides to speak on the supply (ask) or the demand side (bid) of the market, and proposes a volume of assets, where this number is drawn randomly from a uniform distribution. The granularity depends on various factors, including market conventions, the type of assets or goods being traded, and regulatory requirements. In some markets, high granularity is essential to capture small price movements accurately, while in others, coarser granularity is sufficient due to the nature of the assets or goods being traded
How to not get stuck – an ant model showing how negative feedback due to crowding maintains flexibility in ant foraging
Tomer Czaczkes | Published Thursday, December 17, 2015Positive feedback can lead to “trapping” in local optima. Adding a simple negative feedback effect, based on ant behaviour, prevents this trapping
Contract farming in the Mekong Delta's rice supply chain
Hung Nguyen | Published Tuesday, February 05, 2019We study three obstacles of the expansion of contract rice farming in the Mekong Delta (MKD) region. The failure of buyers in building trust-based relationship with small-holder farmers, unattractive offered prices from the contract farming scheme, and limited rice processing capacity have constrained contractors from participating in the large-scale paddy field program. We present an agent-based model to examine the viability of contract farming in the region from the contractor perspective.
The model focuses on financial incentives and trust, which affect the decision of relevant parties on whether to participate and honor a contract. The model is also designed in the context of the MKD’s rice supply chain with two contractors engaging in the contract rice farming scheme alongside an open market, in which both parties can renege on the agreement. We then evaluate the contractors’ performances with different combinations of scenarios related to the three obstacles.
Our results firstly show that a fully-equipped contractor who opportunistically exploits a relatively small proportion (less than 10%) of the contracted farmers in most instances can outperform spot market-based contractors in terms of average profit achieved for each crop. Secondly, a committed contractor who offers lower purchasing prices than the most typical rate can obtain better earnings per ton of rice as well as higher profit per crop. However, those contractors in both cases could not enlarge their contract farming scheme, since either farmers’ trust toward them decreases gradually or their offers are unable to compete with the benefits from a competitor or the spot market. Thirdly, the results are also in agreement with the existing literature that the contract farming scheme is not a cost-effective method for buyers with limited rice processing capacity, which is a common situation among the contractors in the MKD region.
SEDIBASES
Sebastian Rasch | Published Monday, October 20, 2014The Sediba socio-ecolgoical rangeland model is an biomass growth model coupled with a social model of pastoralist behaviour in a commmon pool resource setting. The social subsystem is an empircal ABM.
Agent-based Simulation of Time Management
Hang Xiong | Published Thursday, March 24, 2016 | Last modified Friday, March 25, 2016This model simulates how the strategy one manages time affect the well-being that he/she can obtain.
The Opportunistic Acquisition Model of Stone Tool Raw Material Procurement
Marco Janssen Simen Oestmo Haley Cawthra | Published Friday, April 21, 2017 | Last modified Sunday, March 10, 2019The Opportunistic Acquisition Model (OAM) posits that the archaeological lithic raw material frequencies are due to opportunistic encounters with sources while randomly walking in an environment.

Peer reviewed BHSPopDy (Bighorn sheep population dynamics)
Aniruddha Belsare Ryan Long E Frances Cassirer | Published Tuesday, November 05, 2019This is an agent-based model coded in NetLogo. The model simulates population dynamics of bighorn sheep population in the Hell’s Canyon region of Idaho and will be used to develop a better understanding of pneumonia dynamics in bighorn sheep populations. The overarching objective is to provide a decision-making context for effective management of pneumonia in wild populations of bighorn sheep.
Displaying 10 of 1195 results for "Aad Kessler" clear search