Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1009 results for "Rolf Anker Ims" clear search

Resource distribution effects on optimal foraging theory
Marco Janssen Kim Hill | Published Friday, January 27, 2017The original Ache model is used to explore different distributions of resources on the landscape and it’s effect on optimal strategies of the camps on hunting and camp movement.
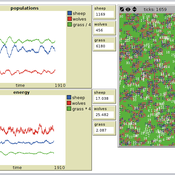
Peer reviewed PPHPC - Predator-Prey for High-Performance Computing
Nuno Fachada | Published Saturday, August 08, 2015 | Last modified Wednesday, November 25, 2015PPHPC is a conceptual model for studying and evaluating implementation strategies for spatial agent-based models (SABMs). It is a realization of a predator-prey dynamic system, and captures important SABMs characteristics.
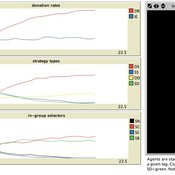
EthnoCultural Tag model (ECT)
Bruce Edmonds David Hales | Published Friday, October 16, 2015 | Last modified Wednesday, May 09, 2018Captures interplay between fixed ethnic markers and culturally evolved tags in the evolution of cooperation and ethnocentrism. Agents evolve cultural tags, behavioural game strategies and in-group definitions. Ethnic markers are fixed.
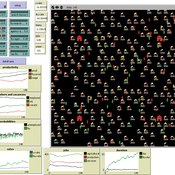
ABSAM model
Marcin Wozniak | Published Monday, August 29, 2016 | Last modified Tuesday, November 08, 2016ABSAM model is an agent-based search and matching model of the local labor market. There are four types of agents in the economy, which cooperate in the artificial world, where behavioral rules were extracted from the labor market search theory.
Emergence of Small-World Networks in an Overlapping-Generations Model of Social Dynamics, Trust and Economic Performance
Bogumił Kamiński Jakub Growiec Katarzyna Growiec | Published Thursday, February 27, 2020We study the impact of endogenous creation and destruction of social ties in an artificial society on aggregate outcomes such as generalized trust, willingness to cooperate, social utility and economic performance. To this end we put forward a computational multi-agent model where agents of overlapping generations interact in a dynamically evolving social network. In the model, four distinct dimensions of individuals’ social capital: degree, centrality, heterophilous and homophilous interactions, determine their generalized trust and willingness to cooperate, altogether helping them achieve certain levels of social utility (i.e., utility from social contacts) and economic performance. We find that the stationary state of the simulated social network exhibits realistic small-world topology. We also observe that societies whose social networks are relatively frequently reconfigured, display relatively higher generalized trust, willingness to cooperate, and economic performance – at the cost of lower social utility. Similar outcomes are found for societies where social tie dissolution is relatively weakly linked to family closeness.
Peer reviewed Evolution of Ecological Communities: Testing Constraint Closure
Steve Peck | Published Sunday, December 06, 2020 | Last modified Friday, April 16, 2021Ecosystems are among the most complex structures studied. They comprise elements that seem both stable and contingent. The stability of these systems depends on interactions among their evolutionary history, including the accidents of organisms moving through the landscape and microhabitats of the earth, and the biotic and abiotic conditions in which they occur. When ecosystems are stable, how is that achieved? Here we look at ecosystem stability through a computer simulation model that suggests that it may depend on what constrains the system and how those constraints are structured. Specifically, if the constraints found in an ecological community form a closed loop, that allows particular kinds of feedback may give structure to the ecosystem processes for a period of time. In this simulation model, we look at how evolutionary forces act in such a way these closed constraint loops may form. This may explain some kinds of ecosystem stability. This work will also be valuable to ecological theorists in understanding general ideas of stability in such systems.
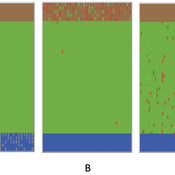
Youth and their Artificial Social Environmental Risk and Promotive Scores (Ya-TASERPS)
JoAnn Lee | Published Wednesday, July 07, 2021 | Last modified Friday, February 24, 2023Risk assessments are designed to measure cumulative risk and promotive factors for delinquency and recidivism, and are used by criminal and juvenile justice systems to inform sanctions and interventions. Yet, these risk assessments tend to focus on individual risk and often fail to capture each individual’s environmental risk. This agent-based model (ABM) explores the interaction of individual and environmental risk on the youth. The ABM is based on an interactional theory of delinquency and moves beyond more traditional statistical approaches used to study delinquency that tend to rely on point-in-time measures, and to focus on exploring the dynamics and processes that evolve from interactions between agents (i.e., youths) and their environments. Our ABM simulates a youth’s day, where they spend time in schools, their neighborhoods, and families. The youth has proclivities for engaging in prosocial or antisocial behaviors, and their environments have likelihoods of presenting prosocial or antisocial opportunities.
Gossip and competitive altruism support cooperation in a Public Good Game
danielevilone | Published Friday, April 16, 2021Here we share the raw results of the social experiments of the paper “Gossip and competitive altruism support cooperation in a Public Good Game” by Giardini, Vilone, Sánchez, Antonioni, under review for Philosophical Transactions B. The experiment is thoroughly described there, in the following we summarize the main features of the experimental setup. The authors are available for further clarifications if requested.
Participants were recruited from the LINEEX subjects pool (University of Valencia Experimental Economics lab). 160 participants mean age = 21.7 years; 89 female) took part in this study in return for a flat payment of 5 EUR and the opportunity to earn an additional payment ranging from 8 to 16 EUR (mean total payment = 17.5 EUR). 80 subjects, divided into 5 groups of 16, took part in the competitive treatment while other 80 subjects participated in the non-competitive treatment. Laboratory experiments were conducted at LINEEX on September 16th and 17th, 2015.
Peer reviewed Are Countertrade credits as flexible and efficient as cash? A novel approach to reducing income inequality using countertrade methodology.
Peter Malliaros | Published Monday, May 03, 2021 | Last modified Tuesday, May 11, 2021The impacts of income inequality can be seen everywhere, regardless of the country or the level of economic development. According to the literature review, income inequality has negative impacts in economic, social, and political variables. Notwithstanding of how well or not countries have done in reducing income inequality, none have been able to reduce it to a Gini Coefficient level of 0.2 or less.
This is the promise that a novel approach called Counterbalance Economics (CBE) provides without the need of increased taxes.
Based on the simulation, introducing the CBE into the Australian, UK, US, Swiss or German economies would result in an overall GDP increase of under 1% however, the level of inequality would be reduced from an average of 0.33 down to an average of 0.08. A detailed explanation of how to use the model, software, and data dependencies along with all other requirements have been included as part of the info tab in the model.
Selective Depolarization by Endogenous Migration in Attraction-Repulsion Opinion Dynamics (NetLogo)
poyeker | Published Tuesday, February 17, 2026This model implements a coupled opinion-mobility agent-based framework in NetLogo, extending Attraction-Repulsion Model (ARM) dynamics with endogenous migration in continuous 2D space.
Each agent has an opinion s in [0,1] and a spatial position (x,y). Agents interact locally within an interaction radius, with exposure-controlled interaction probability. Opinion updates follow ARM rules: attraction for small opinion distance and repulsion for large distance (tolerance threshold T). After social interaction, agents move according to a social-force mechanism that balances attraction to similar neighbors and avoidance of dissimilar neighbors, controlled by orientation bias (approaching goods vs leaving bads). The model also includes an optional exposure-mobility coupling setting.
Main outputs include polarization (P), spatial assortativity (Moran’s I), mixed-neighbor fraction (f_mix), and good-component count (N_g). The model is designed to study phase behavior of polarization and segregation under mobility and tolerance heterogeneity.
…
Displaying 10 of 1009 results for "Rolf Anker Ims" clear search