Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 142 results for "José I Santos" clear search
Models for assessing empowerment through public policies in rural areas in Brazil
Marcos Aurélio Santos da Silva | Published Monday, April 08, 2019Brazil has initiated two territorial public policies for a rural sustainable development, the National Program for Sustainable Development of the Rural Territories (PRONAT) and Citizenship Territory Program (PTC). These public policies aims, as a condition for its effectiveness, the equilibrium of the power relations between actors which participate in the Collegiate for Territorial Development (CODETER) of each Rural Territory. Our research studies the hypotheses that, in the Rural Territories submitted to the PRONAT and PTC public policies, the power and reciprocity relations between actors engaged in the CODETER effectively have evolved in favor of the civil society representatives to the detriment of the public powers, notably the mayors.
The SocLab approach has been applied in two case studies and four models representing the Southern Rural Territory of Sergipe (TRSS) and the São Francisco Rural Territory (TRBSF) were designed for two referential periods, 2008-2012 and 2013-2017. These models were developed to evaluate the empowerment of the civil society in these rural territories due to thes two public policies, PRONAT and PTC.

Societal Simulator v203
Tim Gooding | Published Tuesday, October 01, 2013 | Last modified Friday, November 28, 2014Designed to capture the evolutionary forces of global society.
EU language skills
Marco Civico | Published Sunday, July 07, 2024The objective of this agent-based model is to test different language education orientations and their consequences for the EU population in terms of linguistic disenfranchisement, that is, the inability of citizens to understand EU documents and parliamentary discussions should their native language(s) no longer be official. I will focus on the impact of linguistic distance and language learning. Ideally, this model would be a tool to help EU policy makers make informed decisions about language practices and education policies, taking into account their consequences in terms of diversity and linguistic disenfranchisement. The model can be used to force agents to make certain choices in terms of language skills acquisition. The user can then go on to compare different scenarios in which language skills are acquired according to different rationales. The idea is that, by forcing agents to adopt certain language learning strategies, the model user can simulate policies promoting the acquisition of language skills and get an idea of their impact. In this way the model allows not only to sketch various scenarios of the evolution of language skills among EU citizens, but also to estimate the level of disenfranchisement in each of these scenarios.

Maze with Q-Learning NetLogo extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This is a re-implementation of a the NetLogo model Maze (ROOP, 2006).
This re-implementation makes use of the Q-Learning NetLogo Extension to implement the Q-Learning, which is done only with NetLogo native code in the original implementation.
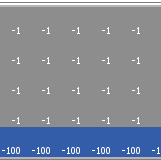
Cliff Walking with Q-Learning NetLogo Extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
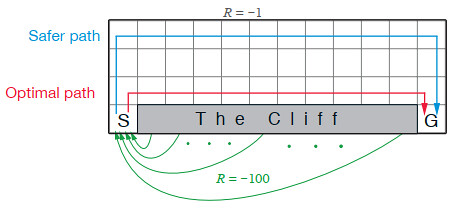
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension
MarPEM: An Agent Based Model to Explore the Effects of Policy Instruments on the Transition of the Maritime Fuel System
G Bas I Nikolic K De Boo Am Vaes - Van De Hulsbeek | Published Thursday, June 15, 2017MarPEM is an agent-based model that can be used to study the effects of policy instruments on the transition away from HFO.
A preliminary extension of the Hemelrijk 1996 model of reciprocal behavior to include feeding
Sean Barton | Published Monday, December 13, 2010 | Last modified Saturday, April 27, 2013A more complete description of the model can be found in Appendix I as an ODD protocol. This model is an expansion of the Hemelrijk (1996) that was expanded to include a simple food seeking behavior.
ADAM: Agent-based Demand and Assignment Model
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013The core algorithm is an agent-based model, which simulates travel patterns on a network based on microscopic decision-making by each traveler.

Walk Away in groups
Athena Aktipis | Published Thursday, March 17, 2016This NetLogo model implements the Walk Away strategy in a spatial public goods game, where individuals have the ability to leave groups with insufficient levels of cooperation.

Peer reviewed NoD-Neg: A Non-Deterministic model of affordable housing Negotiations
Aya Badawy Nuno Pinto Richard Kingston | Published Sunday, September 08, 2024The Non-Deterministic model of affordable housing Negotiations (NoD-Neg) is designed for generating hypotheses about the possible outcomes of negotiating affordable housing obligations in new developments in England. By outcomes we mean, the probabilities of failing the negotiation and/or the different possibilities of agreement.
The model focuses on two negotiations which are key in the provision of affordable housing. The first is between a developer (DEV) who is submitting a planning application for approval and the relevant Local Planning Authority (LPA) who is responsible for reviewing the application and enforcing the affordable housing obligations. The second negotiation is between the developer and a Registered Social Landlord (RSL) who buys the affordable units from the developer and rents them out. They can negotiate the price of selling the affordable units to the RSL.
The model runs the two negotiations on the same development project several times to enable agents representing stakeholders to apply different negotiation tactics (different agendas and concession-making tactics), hence, explore the different possibilities of outcomes.
The model produces three types of outputs: (i) histograms showing the distribution of the negotiation outcomes in all the simulation runs and the probability of each outcome; (ii) a data file with the exact values shown in the histograms; and (iii) a conversation log detailing the exchange of messages between agents in each simulation run.
Displaying 10 of 142 results for "José I Santos" clear search