Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1137 results for "Elena A. Pearce" clear search
HCAM: A Hybrid Climate Assessment Model
Peer-Olaf Siebers | Published Wednesday, November 06, 2019This model is part of a JASSS article that introduce a conceptual framework for developing hybrid (system dynamics and agent-based) integrated assessment models, which focus on examining the human impacts on climate change. This novel modelling approach allows to reuse existing rigid, but well-established integrated assessment models, and adds more flexibility by replacing aggregate stocks with a community of vibrant interacting entities. The model provides a proof-of-concept of the application of this conceptual framework in form of an illustrative example. taking the settings of the US. It is solely created for the purpose of demonstrating our hybrid modelling approach; we do not claim that it has predictive powers.
A Balance Model of Opinion Hyperpolarization
Simon Schweighofer Frank Schweitzer David Garcia Simon Schweighofer | Published Tuesday, December 17, 2019 | Last modified Tuesday, December 17, 2019Contains python3 code to replicate the opinion dynamics model from our (so far unpublished) JASSS sumbission “A Balance Model of Opinion Hyperpolarization”. The main function is run_model(), which returns a dictionary object containing various outcome metrics.
FlowLogo for a real case study
Vahid Aghaie | Published Monday, May 18, 2020Juan Castilla-Rho et al. (2015) developed a platform, named FLowLogo, which integrates a 2D, finite-difference solution of the governing equations of groundwater flow with agent-based simulation. We used this model for Rafsanjan Aquifer, which is located in an arid region in Iran. To use FLowLogo for a real case study, one needs to add GIS shapefiles of boundary conditions and modify the code written in NetLogo a little bit. The FlowLogo model used in our research is presented here.
FeedUS - A global food trade model
Jiaqi Ge | Published Thursday, February 25, 2021 | Last modified Friday, February 26, 2021The purpose of the model is to study the impact of global food trade on food and nutrition security in countries around the world. It will incorporate three main aspects of trade between countries, including a country’s wealth, geographic location, and its trade relationships with other countries (past and ongoing), and can be used to study food and nutrition security across countries in various scenarios, such as climate change, sustainable intensification, waste reduction and dietary change.
Exploring organizational learning in innovation networks. An agent-based model
Sandra Schmid | Published Saturday, March 07, 2015This agent-based model represents a stylized inter-organizational innovation network where firms collaborate with each other in order to generate novel organizational knowledge.
Peter Diamond's Coconut Model (Heterogeneity and Learning)
Sven Banisch Eckehard Olbrich | Published Monday, May 30, 2016Agent-based version of the simple search and barter economy conceived by Peter Diamond in 1982. The model is also known as Coconut Model.
Multi Asset Variable Network Stock Market Model
Matthew Oldham | Published Monday, September 12, 2016 | Last modified Tuesday, October 10, 2017An artifcal stock market model that allows users to vary the number of risky assets as well as the network topology that investors forms in an attempt to understand the dynamics of the market.
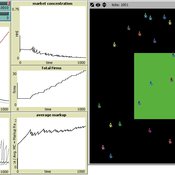
Toward Market Structure as a Complex System: A Web Based Simulation Assignment Implemented in Netlogo
Timothy Kochanski | Published Monday, February 14, 2011 | Last modified Saturday, April 27, 2013This is the model for a paper that is based on a simulation model, programmed in Netlogo, that demonstrates changes in market structure that occur as marginal costs, demand, and barriers to entry change. Students predict and observe market structure changes in terms of number of firms, market concentration, market price and quantity, and average marginal costs, profits, and markups across the market as firms innovate. By adjusting the demand growth and barriers to entry, students can […]

Animal territory formation (Reusable Building Block RBB)
Volker Grimm Stephanie Kramer-Schadt Robert Zakrzewski | Published Sunday, November 12, 2023This is a generic sub-model of animal territory formation. It is meant to be a reusable building block, but not in the plug-and-play sense, as amendments are likely to be needed depending on the species and region. The sub-model comprises a grid of cells, reprenting the landscape. Each cell has a “quality” value, which quantifies the amount of resources provided for a territory owner, for example a tiger. “Quality” could be prey density, shelter, or just space. Animals are located randomly in the landscape and add grid cells to their intial cell until the sum of the quality of all their cells meets their needs. If a potential new cell to be added is owned by another animal, competition takes place. The quality values are static, and the model does not include demography, i.e. mortality, mating, reproduction. Also, movement within a territory is not represented.
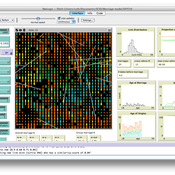
DITCH --- A Model of Inter-Ethnic Partnership Formation
Ruth Meyer Laurence Lessard-Phillips Huw Vasey | Published Wednesday, November 05, 2014 | Last modified Tuesday, February 02, 2016The DITCH model has been developed to investigate partner selection processes, focusing on individual preferences, opportunities for contact, and group size to uncover how these may lead to differential rates of inter-ethnic marriage.
Displaying 10 of 1137 results for "Elena A. Pearce" clear search