Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 289 results for "Jieun Seo" clear search
Peer reviewed Egalitarian sharing
Marcos Pinheiro | Published Friday, January 27, 2023The model explores food distribution patterns that emerge in a small-scale non-agricultural group when individuals follow a set of spatially explicit sharing interaction rules derived from a theory on the evolution of the egalitarian social instinct.
Peer reviewed The foraging potential of the Holocene Cape South Coast of South Africa without the Palaeo-Agulhas Plain
Marco Janssen Colin Wren | Published Monday, August 12, 2019The Palaeo-Agulhas Plain formed an important habitat exploited by Pleistocene hunter-gatherer populations during periods of lower sea level. This productive, grassy habitat would have supported numerous large-bodied ungulates accessible to a population of skilled hunters with the right hunting technology. It also provided a potentially rich location for plant food collection, and along its shores a coastline that moved with the rise and fall of sea levels. The rich archaeological and paleontological records of Pleistocene sites along the modern Cape south coast of South Africa, which would have overlooked the Palaeo-Agulhas Plain during Pleistocene times of lower sea level, provides a paleoarchive of this extinct ecosystem. In this paper, we present a first order illustration of the “palaeoscape modeling” approach advocated by Marean et al. (2015). We use a resourcescape model created from modern studies of habitat productivity without the Palaeo-Agulhas Plain. This is equivalent to predominant Holocene conditions. We then run an agent-based model of the human foraging system to investigate several research questions. Our agent-based approach uses the theoretical framework of optimal foraging theory to model human foraging decisions designed to optimize the net caloric gains within a complex landscape of spatially and temporally variable resources. We find that during the high sea-levels of MIS 5e (+5-6 m asl) and the Holocene, the absence of the Plain left a relatively poor food base supporting a much smaller population relying heavily on edible plant resources from the current Cape flora. Despite high species diversity of plants with edible storage organs, and marine invertebrates, encounter rates with highly profitable resources were low. We demonstrate that without the Palaeo-Agulhas Plain, human populations must have been small and low density, and exploited plant, mammal, and marine resources with relatively low caloric returns. The exposure and contraction of the Palaeo-Agulhas Plain was likely the single biggest driver of behavioral change during periods of climate change through the Pleistocene and into the transition to the Holocene.
NetLogo HIV spread model
Wouter Vermeer | Published Friday, October 25, 2019This model describes the tranmission of HIV by means of unprotected anal intercourse in a population of men-who-have-sex-with-men.
The model is parameterized based on field data from a cohort study conducted in Atlanta Georgia.
Impact of topography and climate change on Magdalenian social networks
Claudine Gravel-Miguel | Published Monday, September 11, 2017The model presented here was created as part of my dissertation. It aims to study the impacts of topography and climate change on prehistoric networks, with a focus on the Magdalenian, which is dated to between 20 and 14,000 years ago.
Peer reviewed AZOI: Another Zone Of Influence model
Cyril Piou | Published Wednesday, July 23, 2014 | Last modified Thursday, December 11, 2014This model reimplement Weiner et al. 2001 Zone Of Influence model to simulate plant growth under competition. The reimplementation in Netlogo and the ODD description in the “info” tab try to be as consistent as possible with the original paper.
Peer reviewed Artificial Anasazi
Marco Janssen | Published Tuesday, September 07, 2010 | Last modified Saturday, April 27, 2013Replication of the well known Artificial Anasazi model that simulates the population dynamics between 800 and 1350 in the Long House Valley in Arizona.

Cluster Analysis
Lars Spång | Published Sunday, January 14, 2018This model illustrates how to apply a simple cluster-analysis on points distributed around 5 centers. The result can be displayed in shades of a color or a spectacular colored pattern.
A replication and extension of the Taylor's Simulation Model of Insurance Market Dynamics in C#
Rei England | Published Sunday, September 24, 2023A simple model is constructed using C# in order to to capture key features of market dynamics, while also producing reasonable results for the individual insurers. A replication of Taylor’s model is also constructed in order to compare results with the new premium setting mechanism. To enable the comparison of the two premium mechanisms, the rest of the model set-up is maintained as in the Taylor model. As in the Taylor example, homogeneous customers represented as a total market exposure which is allocated amongst the insurers.
In each time period, the model undergoes the following steps:
1. Insurers set competitive premiums per exposure unit
2. Losses are generated based on each insurer’s share of the market exposure
3. Accounting results are calculated for each insurer
…
Seeding for information transmission in social networks
Beatrice Nöldeke Ulrike Grote Etti Winter | Published Tuesday, November 03, 2020This model simulates different seeding strategies for information diffusion in a social network adjusted to a case study area in rural Zambia. It systematically evaluates different criteria for seed selection (centrality measures and hierarchy), number of seeds, and interaction effects between seed selection criteria and set size.
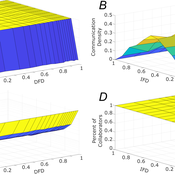
Role of Diversity in Team Performance: the Case of Missing Expertise, an Agent Based Simulations
Tamás Kiss | Published Friday, December 29, 2023This ABM simulates problem solving agents as they work on a set of tasks. Each agent has a trait vector describing their skills. Two agents might form a collaboration if their traits are similar enough. Tasks are defined by a component vector. Agents work on tasks by decreasing tasks’ component vectors towards zero.
The simulation generates agents with given intrapersonal functional diversity (IFD), and dominant function diversity (DFD), and a set of random tasks and evaluates how agents’ traits influence their level of communication and the performance of a team of agents.
Modeling results highlight the importance of the distributions of agents’ properties forming a team, and suggests that for a thorough description of management teams, not only diversity measures based on individual agents, but an aggregate measure is also required.
…
Displaying 10 of 289 results for "Jieun Seo" clear search