Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 806 results NetLogo clear search
Peer reviewed Environmental stochasticity, resource heterogeneity, and the evolution of cooperation
Michaela Starkey Colin Lynch Terry Hunt Carl Lipo | Published Friday, March 14, 2025 | Last modified Wednesday, July 30, 2025The emergence of cooperation in human societies is often linked to environmental constraints, yet the specific conditions that promote cooperative behavior remain an open question. This study examines how resource unpredictability and spatial dispersion influence the evolution of cooperation using an agent-based model (ABM). Our simulations test the effects of rainfall variability and resource distribution on the survival of cooperative and non-cooperative strategies. The results show that cooperation is most likely to emerge when resources are patchy, widely spaced, and rainfall is unpredictable. In these environments, non-cooperators rapidly deplete local resources and face high mortality when forced to migrate between distant patches. In contrast, cooperators—who store and share resources—can better endure extended droughts and irregular resource availability. While rainfall stochasticity alone does not directly select for cooperation, its interaction with resource patchiness and spatial constraints creates conditions where cooperative strategies provide a survival advantage. These findings offer broader insights into how environmental uncertainty shapes social organization in resource-limited settings. By integrating ecological constraints into computational modeling, this study contributes to a deeper understanding of the conditions that drive cooperation across diverse human and animal systems.
How Does Culture Affect Vaccination Opinion Polarisation?
Teng Li | Published Monday, March 10, 2025This model is to explore how individuals’ cultural backgrounds may play a role in their Covid vaccination decision-making. Two cultural dimensions of collectivism/individualism and power distance are considered. Through the experimental scenarios, we find that Covid-vaccination opinions in collectivist societies can also be considerably polarised, if the power distance is less and authorities less centralised. This result complements the popular idea that cultural collectivism is usually associated with a high degree of social consensus. Hopefully, this study will help explain countries’ difference in the response of Covid vaccination programs.
Multi-agent model of the spread of climate change denial
Kalina Maria Piskorska Martin Takáč | Published Monday, March 03, 2025This NetLogo model simulates the spread of climate change beliefs within a population of individuals. Each believer has an initial belief level, which changes over time due to interactions with other individuals and exposure to media. The aim of the model is to identify possible methods for reducing climate change denial.
Peer reviewed WaDemEsT-Water Demand Estimation Tool for Residential Areas
Kamil Aybuğa | Published Tuesday, February 18, 2025This model simulates household water consumption patterns in an urban environment. Its current setup compares monthly water consumption data, and the results of a daily heuristic water demand model with the simulation results produced by household demographics that is fine tuned via some base demand model. It’s designed to estimate and analyze water demand based on various factors including household demographics, daily routines of residents (working, weekending, vacation patterns), weather conditions (temperature and precipitation), appliance usage patterns, seasonal variations, and special periods such as weekends and holidays. The model aims to help understand how different factors influence residential water consumption and can be used for water demand forecasting and management.
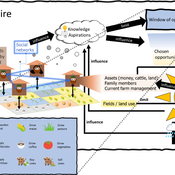
3spire: an agent-based model for exploring aspiration adaptation theory and its implications on smallholder farmers in Ethiopia
ateeuw Yue Dou Markus A Meyer Andrew Nelson | Published Sunday, February 16, 20253spire is an ABM where farming households make management decisions aimed at satisficing along the aspirational dimensions: food self-sufficiency, income, and leisure. Households decision outcomes depend on their social networks, knowledge, assets, household needs, past management, and climate/market trends
An agent-based model to simulate field-specific nitrogen fertilizer applications in grasslands
Maria Haensel Thomas Schmitt Andrea Kaim Sylvia Helena Annuth Thomas Koellner | Published Sunday, February 09, 2025Grasslands have a large share of the world’s land cover and their sustainable management is important for the protection and provisioning of grassland ecosystem services. The question of how to manage grassland sustainably is becoming increasingly important, especially in view of climate change, which on the one hand extends the vegetation period (and thus potentially allows use intensification) and on the other hand causes yield losses due to droughts. Fertilization plays an important role in grassland management and decisions are usually made at farm level. Data on fertilizer application rates are crucial for an accurate assessment of the effects of grassland management on ecosystem services. However, these are generally not available on farm/field scale. To close this gap, we present an agent-based model for Fertilization In Grasslands (FertIG). Based on animal, land-use, and cutting data, the model estimates grassland yields and calculates field-specific amounts of applied organic and mineral nitrogen on grassland (and partly cropland). Furthermore, the model considers different legal requirements (including fertilization ordinances) and nutrient trade among farms. FertIG was applied to a grassland-dominated region in Bavaria, Germany comparing the effects of changes in the fertilization ordinance as well as nutrient trade. The results show that the consideration of nutrient trade improves organic fertilizer distribution and leads to slightly lower Nmin applications. On a regional scale, recent legal changes (fertilization ordinance) had limited impacts. Limiting the maximum applicable amount of Norg to 170 kg N/ha fertilized area instead of farm area as of 2020 hardly changed fertilizer application rates. No longer considering application losses in the calculation of fertilizer requirements had the strongest effects, leading to lower supplementary Nmin applications. The model can be applied to other regions in Germany and, with respective adjustments, in Europe. Generally, it allows comparing the effects of policy changes on fertilization management at regional, farm and field scale.
An Agent-Based Model of Indirect Minority Influence on Social Change
Jiin Jung | Published Wednesday, February 05, 2025This model demonstrates how different psychological mechanisms and network structures generate various patterns of cultural dynamics including cultural diversity, polarization, and majority dominance, as explored by Jung, Bramson, Crano, Page, and Miller (2021). It focuses particularly on the psychological mechanisms of indirect minority influence, a concept introduced by Serge Moscovici (1976, 1980)’s genetic model of social influence, and validates how such influence can lead to social change.
Autonomy or control? An agent-based study of self-organising versus centralised task allocation
Shaoni Wang | Published Wednesday, January 29, 2025The aim of our model is to investigate the team dynamics through two types of task allocation strategies, with a focus on the dynamic interplay between individual needs and group performance. To achieve this goal, we have formulated an agent-based model (ABM) to formalize Deci & Ryan’s self-determination theory (SDT) and explore the social dynamics that govern the relationship between individual and group levels of team performance.
ABM Code: Locating Cultural Holes Brokers in Diffusion Dynamics across Bright Symbolic Boundaries
Diego Leal | Published Thursday, January 23, 2025The code and data in this repository are associated with the article titled:
Leal, Diego F. 2025. “Locating Cultural Holes Brokers in Diffusion Dynamics across Bright Symbolic Boundaries.” Sociological Methods & Research OnlineFirst https://doi.org/10.1177/00491241251322517
The NetLogo code (version 6.4.0) is designed to be a standalone piece of code although it uses the ‘nw’ and ‘matrix’ extensions that come integrated with NetLogo 6.4.0. The code was ran on a Windows 10 x 64 machine.
BarterNet is a platform for modeling early barter networks with the aim of learning how supply and demand for a good determine if traders will learn to use that good as a form of money. Traders use a good as money when they offer to trade for it even if they can’t consume it, but believe that they can subsequently trade it for a good they can consume in the near future.
Displaying 10 of 806 results NetLogo clear search