Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 367 results for "Emmanuel Mhike Hove" clear search

Agent-based model of WiFi tracking system in urban environment
Christopher Thron Khoi Tran | Published Friday, April 21, 2017This code simulates the WiFi user tracking system described in: Thron et al., “Design and Simulation of Sensor Networks for Tracking Wifi Users in Outdoor Urban Environments”. Testbenches used to create the figures in the paper are included.
Expectation-Based Bayesian Belief Revision
C Merdes Momme Von Sydow Ulrike Hahn | Published Monday, June 19, 2017 | Last modified Monday, August 06, 2018This model implements a Bayesian belief revision model that contrasts an ideal agent in possesion of true likelihoods, an agent using a fixed estimate of trusting its source of information, and an agent updating its trust estimate.
Peer reviewed Empathy & Power
J M Applegate Ned Wellman | Published Monday, November 13, 2017 | Last modified Thursday, December 21, 2017The purpose of this model is to explore the effects of different power structures on a cross-functional team’s prosocial decision making. Are certain power distributions more conducive to the team making prosocial decisions?
A network agent-based model of ethnocentrism and intergroup cooperation
Ross Gore | Published Sunday, October 27, 2019We present a network agent-based model of ethnocentrism and intergroup cooperation in which agents from two groups (majority and minority) change their communality (feeling of group solidarity), cooperation strategy and social ties, depending on a barrier of “likeness” (affinity). Our purpose was to study the model’s capability for describing how the mechanisms of preexisting markers (or “tags”) that can work as cues for inducing in-group bias, imitation, and reaction to non-cooperating agents, lead to ethnocentrism or intergroup cooperation and influence the formation of the network of mixed ties between agents of different groups. We explored the model’s behavior via four experiments in which we studied the combined effects of “likeness,” relative size of the minority group, degree of connectivity of the social network, game difficulty (strength) and relative frequencies of strategy revision and structural adaptation. The parameters that have a stronger influence on the emerging dominant strategies and the formation of mixed ties in the social network are the group-tag barrier, the frequency with which agents react to adverse partners, and the game difficulty. The relative size of the minority group also plays a role in increasing the percentage of mixed ties in the social network. This is consistent with the intergroup ties being dependent on the “arena” of contact (with progressively stronger barriers from e.g. workmates to close relatives), and with measures that hinder intergroup contact also hindering mutual cooperation.
Risk-Sharing under Heterogeneity: NetLogo simulation
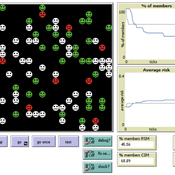
Eva Vriens | Published Monday, February 28, 2022Motivated by the emergence of new Peer-to-Peer insurance organizations that rethink how insurance is organized, we propose a theoretical model of decision-making in risk-sharing arrangements with risk heterogeneity and incomplete information about the risk distribution as core features. For these new, informal organisations, the available institutional solutions to heterogeneity (e.g., mandatory participation or price differentiation) are either impossible or undesirable. Hence, we need to understand the scope conditions under which individuals are motivated to participate in a bottom-up risk-sharing setting. The model puts forward participation as a utility maximizing alternative for agents with higher risk levels, who are more risk averse, are driven more by solidarity motives, and less susceptible to cost fluctuations. This basic micro-level model is used to simulate decision-making for agent populations in a dynamic, interdependent setting. Simulation results show that successful risk-sharing arrangements may work if participants are driven by motivations of solidarity or risk aversion, but this is less likely in populations more heterogeneous in risk, as the individual motivations can less often make up for the larger cost deficiencies. At the same time, more heterogeneous groups deal better with uncertainty and temporary cost fluctuations than more homogeneous populations do. In the latter, cascades following temporary peaks in support requests more often result in complete failure, while under full information about the risk distribution this would not have happened.
SimPioN - Simulating Path dependence in inter-organisational Networks
Nanda Wijermans Frithjof Stöppler | Published Monday, January 11, 2021The SimPioN model aims to abstractly reproduce and experiment with the conditions under which a path-dependent process may lead to a (structural) network lock-in in interorganisational networks.
Path dependence theory is constructed around a process argumentation regarding three main elements: a situation of (at least) initially non-ergodic (unpredictable with regard to outcome) starting conditions in a social setting; these become reinforced by the workings of (at least) one positive feedback mechanism that increasingly reduces the scope of conceivable alternative choices; and that process finally results in a situation of lock-in, where any alternatives outside the already adopted options become essentially impossible or too costly to pursue despite (ostensibly) better options theoretically being available.
The purpose of SimPioN is to advance our understanding of lock-ins arising in interorganisational networks based on the network dynamics involving the mechanism of social capital. This mechanism and the lock-ins it may drive have been shown above to produce problematic consequences for firms in terms of a loss of organisational autonomy and strategic flexibility, especially in high-tech knowledge-intensive industries that rely heavily on network organising.
…
Peer reviewed Price Evolution with Expectations
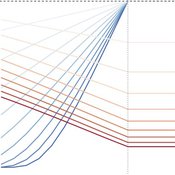
J M Applegate Gesine Steudel Armin Haas Carlo Jaeger | Published Friday, September 10, 2021The Price Evolution with Expectations model provides the opportunity to explore the question of non-equilibrium market dynamics, and how and under which conditions an economic system converges to the classically defined economic equilibrium. To accomplish this, we bring together two points of view of the economy; the classical perspective of general equilibrium theory and an evolutionary perspective, in which the current development of the economic system determines the possibilities for further evolution.
The Price Evolution with Expectations model consists of a representative firm producing no profit but producing a single good, which we call sugar, and a representative household which provides labour to the firm and purchases sugar.The model explores the evolutionary dynamics whereby the firm does not initially know the household demand but eventually this demand and thus the correct price for sugar given the household’s optimal labour.
The model can be run in one of two ways; the first does not include money and the second uses money such that the firm and/or the household have an endowment that can be spent or saved. In either case, the household has preferences for leisure and consumption and a demand function relating sugar and price, and the firm has a production function and learns the household demand over a set number of time steps using either an endogenous or exogenous learning algorithm. The resulting equilibria, or fixed points of the system, may or may not match the classical economic equilibrium.
Sensitivity of a population submitted to floods to unknown upcoming floods and parameters of the dynamics
Sylvie Huet | Published Wednesday, September 22, 2021This work is a java implementation of a study of the viability of a population submitted to floods. The population derives some benefit from living in a certain environment. However, in this environment, floods can occur and cause damage. An individual protection measure can be adopted by those who wish and have the means to do so. The protection measure reduces the damage in case of a flood. However, the effectiveness of this measure deteriorates over time. Individual motivation to adopt this measure is boosted by the occurrence of a flood. Moreover, the public authorities can encourage the population to adopt this measure by carrying out information campaigns, but this comes at a cost. People’s decisions are modelled based on the Protection Motivation Theory (Rogers1975, Rogers 1997, Maddux1983) arguing that the motivation to protect themselves depends on their perception of risk, their capacity to cope with risk and their socio-demographic characteristics.
While the control designing proper informations campaigns to remain viable every time is computed in the work presented in https://www.comses.net/codebases/e5c17b1f-0121-4461-9ae2-919b6fe27cc4/releases/1.0.0/, the aim of the present work is to produce maps of probable viability in case the serie of upcoming floods is unknown as well as much of the parameters for the population dynamics. These maps are bi-dimensional, based on the value of known parameters: the current average wealth of the population and their actual or possible future annual revenues.

Peer reviewed FishCensus
Miguel Pais | Published Tuesday, December 06, 2016 | Last modified Thursday, February 09, 2017The FishCensus model simulates underwater visual census methods, where a diver estimates the abundance of fish. A separate model is used to shape species behaviours and save them to a file that can be shared and used by the counting model.
ABODE - Agent Based Model of Origin Destination Estimation
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013The agent based model matches origins and destinations using employment search methods at the individual level.
Displaying 10 of 367 results for "Emmanuel Mhike Hove" clear search