Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 81 results for "Alessandro K Cerutti" clear search
An Agent-Based Model of Flood Risk and Insurance
J Dubbelboer I Nikolic K Jenkins J Hall | Published Monday, July 27, 2015 | Last modified Monday, October 03, 2016A model to show the effects of flood risk on a housing market; the role of flood protection for risk reduction; the working of the existing public-private flood insurance partnership in the UK, and the proposed scheme ‘Flood Re’.
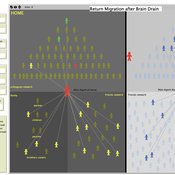
RETURN MIGRATION AFTER BRAIN DRAIN: A SIMULATION APPROACH
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Friday, June 21, 2013This model, realized on the NetLogo platform, compares utility levels at home and abroad to simulate agents’ migration and their eventual return. Our model is based on two fundamental individual features, i.e. risk aversion and initial expectation, which characterize the dynamics of different agents according to the evolution of their social contacts.
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
A land-use model to illustrate ambiguity in design
Julia Schindler | Published Monday, October 15, 2012 | Last modified Friday, January 13, 2017This is an agent-based model that allows to test alternative designs for three model components. The model was built using the LUDAS design strategy, while each alternative is in line with the strategy. Using the model, it can be shown that alternative designs, though built on the same strategy, lead to different land-use patterns over time.
A Consumer in the Jungle of Product Differentiation
Alessandro Pluchino Andrea Rapisarda Alessio Emanuele Biondo Alfio Giarlotta | Published Tuesday, December 22, 2015Building upon the distance-based Hotelling’s differentiation idea, we describe the behavioral experience of several prototypes of consumers, who walk a hypothetical cognitive path in an attempt to maximize their satisfaction.

NOMAD: Near–Off Mobility under Aspiration Dynamics
Alejandro Platas López | Published Wednesday, December 17, 2025NOMAD is an agent-based model of firm location choice between two aggregate regions (“near” and “off”) under logistics uncertainty. Firms occupy sites characterised by attractiveness and logistics risk, earn a risk-adjusted payoff that depends on regional costs (wages plus congestion) and an individual risk-tolerance trait, and update location choices using aspiration-based satisficing rules with switching frictions. Logistics risk evolves endogenously on occupied sites through a region-specific absorption mechanism (good/bad events that reduce/increase risk), while congestion feeds back into regional costs via regional shares and local crowding. Runs stop endogenously once the near-region share becomes quasi-stable after burn-in, and the model records time series and quasi-stable outcomes such as near/off composition, switching intensity, costs, average risk, and average risk tolerance.
FilterBubbles_in_Carley1991
Benoît Desmarchelier | Published Wednesday, May 21, 2025The model is an extension of: Carley K. (1991) “A theory of group stability”, American Sociological Review, vol. 56, pp. 331-354.
The original model from Carley (1991) works as follows:
- Agents know or ignore a series of knowledge facts;
- At each time step, each agent i choose a partner j to interact with at random, with a probability of choice proportional to the degree of knowledge facts they have in common.
- Agents interact synchronously. As such, interaction happens only if the partnert j is not already busy interacting with someone else.
…
MarPEM: An Agent Based Model to Explore the Effects of Policy Instruments on the Transition of the Maritime Fuel System
G Bas I Nikolic K De Boo Am Vaes - Van De Hulsbeek | Published Thursday, June 15, 2017MarPEM is an agent-based model that can be used to study the effects of policy instruments on the transition away from HFO.
FEARLUS-SPOMM
Dawn Parker Gary Polhill Nick Gotts Alistair Law Luis Izquierdio Alessandro Gimona Lee-Ann Sutherland | Published Friday, March 25, 2016This is a coupled conceptual model of agricultural land decision-making and incentivisation and species metacommunities.

Peer reviewed Zimbabwe Agro-Pastoral Management Model (ZAPMM): Musimboti wevanhu, zvipfuo nezvirimwa
MV Eitzel Solera Kleber Tulio Neves Jon Solera Kenneth B Wilson Abraham Mawere Ndlovu Aaron C Fisher André Veski Oluwasola E Omoju Emmanuel Mhike Hove | Published Tuesday, June 19, 2018This model has been created with and for the researcher-farmers of the Muonde Trust (http://www.muonde.org/), a registered Zimbabwean non-governmental organization dedicated to fostering indigenous innovation. Model behaviors and parameters (mashandiro nemisiyano nedzimwe model) derive from a combination of literature review and the collected datasets from Muonde’s long-term (over 30 years) community-based research. The goals of this model are three-fold (muzvikamu zvitatu):
A) To represent three components of a Zimbabwean agro-pastoral system (crops, woodland grazing area, and livestock) along with their key interactions and feedbacks and some of the human management decisions that may affect these components and their interactions.
B) To assess how climate variation (implemented in several different ways) and human management may affect the sustainability of the system as measured by the continued provisioning of crops, livestock, and woodland grazing area.
C) To provide a discussion tool for the community and local leaders to explore different management strategies for the agro-pastoral system (hwaro/nzira yekudyidzana kwavanhu, zvipfuo nezvirimwa), particularly in the face of climate change.
Displaying 10 of 81 results for "Alessandro K Cerutti" clear search