Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 217 results for "Andreas Flache" clear search
While the world’s total urban population continues to grow, not all cities are witnessing such growth, some are actually shrinking. This shrinkage causes several problems to emerge including population loss, economic depression, vacant properties and the contraction of housing markets. Such problems challenge efforts to make cities sustainable. While there is a growing body of work on study shrinking cities, few explore such a phenomenon from the bottom up using dynamic computational models. To overcome this issue this paper presents an spatially explicit agent-based model stylized on the Detroit Tri-county area, an area witnessing shrinkage. Specifically, the model demonstrates how through the buying and selling of houses can lead to urban shrinkage from the bottom up. The model results indicate that along with the lower level housing transactions being captured, the aggregated level market conditions relating to urban shrinkage are also captured (i.e., the contraction of housing markets). As such, the paper demonstrates the potential of simulation to explore urban shrinkage and potentially offers a means to test polices to achieve urban sustainability.
Modeling information Asymmetries in Tourism
Jacopo A. Baggio Rodolfo Baggio | Published Monday, January 09, 2012 | Last modified Saturday, April 27, 2013A very simple model elaborated to explore what may happens when buyers (travelers) have more information than sellers (tourist destinations)
Residents planned behaviour of waste sorting to explore urban situations
Jonathan Edgardo Cohen | Published Wednesday, June 07, 2023 | Last modified Thursday, March 14, 2024Municipal waste management (MWM) is essential for urban development. Efficient waste management is essential for providing a healthy and clean environment, for reducing GHGs and for increasing the amount of material recycled. Waste separation at source is perceived as an effective MWM strategy that relays on the behaviour of citizens to separate their waste in different fractions. The strategy is straightforward, and many cities have adopted the strategy or are working to implement it. However, the success of such strategy depends on adequate understanding of the drivers of the behaviour of proper waste sorting. The Theory of Planned Behaviour (TPB) has been extensively applied to explain the behaviour of waste sorting and contributes to determining the importance of different psychological constructs. Although, evidence shows its validity in different contexts, without exploring how urban policies and the built environment affect the TPB, its application to urban challenges remains unlocked. To date, limited research has focused in exposing how different urban situations such as: distance to waste bins, conditions of recycling facilities or information campaigns affect the planned behaviour of waste separation. To fill this gap, an agent-based model (ABM) of residents capable of planning the behaviour of waste separation is developed. The study is a proof of concept that shows how the TPB can be combined with simulations to provide useful insights to evaluate different urban planning situations. In this paper we depart from a survey to capture TPB constructs, then Structural Equation Modelling (SEM) is used to validate the TPB hypothesis and extract the drivers of the behaviour of waste sorting. Finally, the development of the ABM is detailed and the drivers of the TPB are used to determine how the residents behave. A low-density and a high-density urban scenario are used to extract policy insights. In conclusion, the integration between the TPB into ABMs can help to bridge the knowledge gap between can provide a useful insight to analysing and evaluating waste management scenarios in urban areas. By better understanding individual waste sorting behaviour, we can develop more effective policies and interventions to promote sustainable waste management practices.
Soy2Grow-ABM-V1
Siavash Farahbakhsh | Published Monday, January 20, 2025The Soy2Grow ABM aims to simulate the adoption of soybean production in Flanders, Belgium. The model primarily considers two types of agents as farmers: 1) arable and 2) dairy farmers. Each farmer, based on its type, assesses the feasibility of adopting soybean cultivation. The feasibility assessment depends on many interrelated factors, including price, production costs, yield, disease, drought (i.e., environmental stress), social pressure, group formations, learning and skills, risk-taking, subsidies, target profit margins, tolerance to bad experiences, etc. Moreover, after adopting soybean production, agents will reassess their performance. If their performance is unsatisfactory, an agent may opt out of soy production. Therefore, one of the main outcomes to look for in the model is the number of adopters over time.
The main agents are farmers. Generally, factors influencing farmers’ decision-making are divided into seven main areas: 1) external environmental factors, 2) cooperation and learning (with slight differences depending on whether they are arable or dairy farmers), 3) crop-specific factors, 4) economics, 5) support frameworks, 6) behavioral factors, and 7) the role of mobile toasters (applicable only to dairy farmers).
Moreover, factors not only influence decision-making but also interact with each other. Specifically, external environmental factors (i.e., stress) will result in lower yield and quality (protein content). The reducing effect, identified during participatory workshops, can reach 50 %. Skills can grow and improve yield; however, their growth has a limit and follows different learning curves depending on how individualistic a farmer is. During participatory workshops, it was identified that, contrary to cooperative farmers, individualistic farmers may learn faster and reach their limits more quickly. Furthermore, subsidies directly affect revenues and profit margins; however, their impact may disappear when they are removed. In the case of dairy farmers, mobile toasters play an important role, adding toasting and processing costs to those producing soy for their animal feed consumption.
Last but not least, behavioral factors directly influence the final adoption decision. For example, high risk-taking farmers may adopt faster, whereas more conservative farmers may wait for their neighbors to adopt first. Farmers may evaluate their success based on their own targets and may also consider other crops rather than soy.
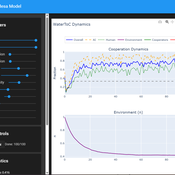
Tragedy of the Commons with Environmental Feedback: A Model of Human-AI Socio-Environmental Water Dilemma
Ivana Malcic Luka Waronig Andrew Crossley | Published Saturday, July 05, 2025 | Last modified Sunday, July 06, 2025This project is an interactive agent-based model simulating consumption of a shared, renewable resource using a game-theoretic framework with environmental feedback. The primary function of this model was to test how resource-use among AI and human agents degrades the environment, and to explore the socio-environmental feedback loops that lead to complex emergent system dynamics. We implemented a classic game theoretic matrix which decides agents´ strategies, and added a feedback loop which switches between strategies in pristine vs degraded environments. This leads to cooperation in bad environments, and defection in good ones.
Despite this use, it can be applicable for a variety of other scenarios including simulating climate disasters, environmental sensitivity to resource consumption, or influence of environmental degradation to agent behaviour.
The ABM was inspired by the Weitz et. al. (2016, https://pubmed.ncbi.nlm.nih.gov/27830651/) use of environmental feedback in their paper, as well as the Demographic Prisoner’s Dilemma on a Grid model (https://mesa.readthedocs.io/stable/examples/advanced/pd_grid.html#demographic-prisoner-s-dilemma-on-a-grid). The main innovation is the added environmental feedback with local resource replenishment.
Beyond its theoretical insights into coevolutionary dynamics, it serves as a versatile tool with several practical applications. For urban planners and policymakers, the model can function as a ”digital sandbox” for testing the impacts of locating high-consumption industrial agents, such as data centers, in proximity to residential communities. It allows for the exploration of different urban densities, and the evaluation of policy interventions—such as taxes on defection or subsidies for cooperation—by directly modifying the agents’ resource consumptions to observe effects on resource health. Furthermore, the model provides a framework for assessing the resilience of such socio-environmental systems to external shocks.
…
OMOLAND-CA: An Agent-Based Modeling of Rural Households’ Adaptation to Climate Change
Atesmachew Hailegiorgis Andrew Crooks Claudio Cioffi-Revilla | Published Tuesday, July 25, 2017 | Last modified Tuesday, July 10, 2018The purpose of the OMOLAND-CA is to investigate the adaptive capacity of rural households in the South Omo zone of Ethiopia with respect to variation in climate, socioeconomic factors, and land-use at the local level.

MEGADAPT - Socio-hydrological risk model - Theoretical (no data) implementation
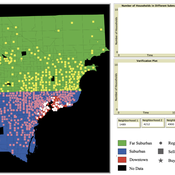
Marco Janssen Andres Baeza-Castro Luis Bojorquez Hallie Eakin | Published Wednesday, February 06, 2019The model simulates the decisions of residents and a water authority to respond to socio-hydrological hazards. Residents from neighborhoods are located in a landscape with topographic complexity and two problems: water scarcity in the peripheral neighborhoods at high altitude and high risk of flooding in the lowlands, at the core of the city. The role of the water authority is to decide where investments in infrastructure should be allocated to reduce the risk to water scarcity and flooding events in the city, and these decisions are made via a multi-objective site selection procedure. This procedure accounts for the interdependencies and feedback between the urban landscape and a policy scenario that defines the importance, or priorities, that the authority places on four criteria.
Neighborhoods respond to the water authority decisions by protesting against the lack of investment and the level of exposure to water scarcity and flooding. Protests thus simulate a form of feedback between local-level outcomes (flooding and water scarcity) and higher-level decision-making. Neighborhoods at high altitude are more likely to be exposed to water scarcity and lack infrastructure, whereas neighborhoods in the lowlands tend to suffer from recurrent flooding. The frequency of flooding is also a function of spatially uniform rainfall events. Likewise, neighborhoods at the periphery of the urban landscape lack infrastructure and suffer from chronic risk of water scarcity.
The model simulates the coupling between the decision-making processes of institutional actors, socio-political processes and infrastructure-related hazards. In the documentation, we describe details of the implementation in NetLogo, the description of the procedures, scheduling, and the initial conditions of the landscape and the neighborhoods.
This work was supported by the National Science Foundation under Grant No. 1414052, CNH: The Dynamics of Multi-Scalar Adaptation in Megacities (PI Hallie Eakin).
Peer reviewed Coupled demographic dynamics of herd and household in pastoral systems
Mark Moritz Ian M Hamilton Andrew Yoak Abigail Buffington Chelsea E Hunter Daniel C Peart | Published Saturday, April 08, 2023This purpose of this model is to understand how the coupled demographic dynamics of herds and households constrain the growth of livestock populations in pastoral systems.
Forager mobility and interaction
L S Premo | Published Thursday, January 10, 2013 | Last modified Saturday, April 27, 2013This is a relatively simple foraging-radius model, as described first by Robert Kelly, that allows one to quantify the effect of increased logistical mobility (as represented by increased effective foraging radius, r_e) on the likelihood that 2 randomly placed central place foragers will encounter one another within 5000 time steps.
Epidemic Simulation with Transportation Simulation
FG Econophysics FG Econophysics | Published Monday, March 01, 2021The Episim framework builds upon the established transportation simulation MATSim and is capable of tracking agents’ movements within a network and thus computing infection chains. Several characteristics of the virus and the environment can be parametred, whilst the infection dynamics is computed based upon a compartment model. The spread of the virus can be mitigated by restricting the agents’ activity in certain places.
Displaying 10 of 217 results for "Andreas Flache" clear search