Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 218 results for "Blanca Rosa Cases Gutiérrez" clear search
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.

Agent-based model of WiFi tracking system in urban environment
Christopher Thron Khoi Tran | Published Friday, April 21, 2017This code simulates the WiFi user tracking system described in: Thron et al., “Design and Simulation of Sensor Networks for Tracking Wifi Users in Outdoor Urban Environments”. Testbenches used to create the figures in the paper are included.
Peer reviewed COMOKIT
Patrick Taillandier Alexis Drogoul Benoit Gaudou Kevin Chapuis Nghi Huyng Quang Doanh Nguyen Ngoc Arthur Brugière Pierre Larmande Marc Choisy Damien Philippon | Published Tuesday, May 26, 2020 | Last modified Wednesday, July 01, 2020In the face of the COVID-19 pandemic, public health authorities around the world have experimented, in a short period of time, with various combinations of interventions at different scales. However, as the pandemic continues to progress, there is a growing need for tools and methodologies to quickly analyze the impact of these interventions and answer concrete questions regarding their effectiveness, range and temporality.
COMOKIT, the COVID-19 modeling kit, is such a tool. It is a computer model that allows intervention strategies to be explored in silico before their possible implementation phase. It can take into account important dimensions of policy actions, such as the heterogeneity of individual responses or the spatial aspect of containment strategies.
In COMOKIT, built using the agent-based modeling and simulation platform GAMA, the profiles, activities and interactions of people, person-to-person and environmental transmissions, individual clinical statuses, public health policies and interventions are explicitly represented and they all serve as a basis for describing the dynamics of the epidemic in a detailed and realistic representation of space.
…
RiskNetABM
Birgit Müller Jürgen Groeneveld Karin Frank Meike Will Friederike Lenel | Published Monday, July 20, 2020 | Last modified Monday, May 03, 2021The fight against poverty is an urgent global challenge. Microinsurance is promoted as a valuable instrument for buffering income losses due to health or climate-related risks of low-income households in developing countries. However, apart from direct positive effects they can have unintended side effects when insured households lower their contribution to traditional arrangements where risk is shared through private monetary support.
RiskNetABM is an agent-based model that captures dynamics between income losses, insurance payments and informal risk-sharing. The model explicitly includes decisions about informal transfers. It can be used to assess the impact of insurance products and informal risk-sharing arrangements on the resilience of smallholders. Specifically, it allows to analyze whether and how economic needs (i.e. level of living costs) and characteristics of extreme events (i.e. frequency, intensity and type of shock) influence the ability of insurance and informal risk-sharing to buffer income shocks. Two types of behavior with regard to private monetary transfers are explicitly distinguished: (1) all households provide transfers whenever they can afford it and (2) insured households do not show solidarity with their uninsured peers.
The model is stylized and is not used to analyze a particular case study, but represents conditions from several regions with different risk contexts where informal risk-sharing networks between smallholder farmers are prevalent.
…
Peer reviewed Price Evolution with Expectations
J M Applegate Gesine Steudel Armin Haas Carlo Jaeger | Published Friday, September 10, 2021The Price Evolution with Expectations model provides the opportunity to explore the question of non-equilibrium market dynamics, and how and under which conditions an economic system converges to the classically defined economic equilibrium. To accomplish this, we bring together two points of view of the economy; the classical perspective of general equilibrium theory and an evolutionary perspective, in which the current development of the economic system determines the possibilities for further evolution.
The Price Evolution with Expectations model consists of a representative firm producing no profit but producing a single good, which we call sugar, and a representative household which provides labour to the firm and purchases sugar.The model explores the evolutionary dynamics whereby the firm does not initially know the household demand but eventually this demand and thus the correct price for sugar given the household’s optimal labour.
The model can be run in one of two ways; the first does not include money and the second uses money such that the firm and/or the household have an endowment that can be spent or saved. In either case, the household has preferences for leisure and consumption and a demand function relating sugar and price, and the firm has a production function and learns the household demand over a set number of time steps using either an endogenous or exogenous learning algorithm. The resulting equilibria, or fixed points of the system, may or may not match the classical economic equilibrium.
Large-scale land acqusitions and smallholder food security
Tim Williams | Published Thursday, September 16, 2021Large-scale land acquisitions (LSLAs) threaten smallholder livelihoods globally. Despite more than a decade of research on the LSLA phenomenon, it remains a challenge to identify governance conditions that may foster beneficial outcomes for both smallholders and investors. One potentially promising strategy toward this end is contract farming (CF), which more directly involves smallholder households in commodity production than conditions of acquisition and displacement.
To improve understanding of how CF may mediate the outcomes of LSLAs, we developed an agent-based model of smallholder livelihoods, which we used as a virtual laboratory to experiment on a range of hypothetical LSLA and CF implementation scenarios.
The model represents a community of smallholder households in a mixed crop-livestock system. Each agent farms their own land and manages a herd of livestock. Agents can also engage in off-farm employment, for which they earn a fixed wage and compete for a limited number of jobs. The principal model outputs include measures of household food security (representing access to a single, staple food crop) and agricultural production (of a single, staple food crop).
…
A Data-Driven Approach of Layout Evaluation for Electric Vehicle Charging Infrastructure Using Agent-Based Simulation and GIS
yue zhang | Published Thursday, September 21, 2023The development and popularisation of new energy vehicles have become a global consensus. The shortage and unreasonable layout of electric vehicle charging infrastructure (EVCI) have severely restricted the development of electric vehicles. In the literature, many methods can be used to optimise the layout of charging stations (CSs) for producing good layout designs. However, more realistic evaluation and validation should be used to assess and validate these layout options. This study suggested an agent-based simulation (ABS) model to evaluate the layout designs of EVCI and simulate the driving and charging behaviours of electric taxis (ETs). In the case study of Shenzhen, China, GPS trajectory data were used to extract the temporal and spatial patterns of ETs, which were then used to calibrate and validate the actions of ETs in the simulation. The ABS model was developed in a GIS context of an urban road network with travelling speeds of 24 h to account for the effects of traffic conditions. After the high-resolution simulation, evaluation results of the performance of EVCI and the behaviours of ETs can be provided in detail and in summary. Sensitivity analysis demonstrates the accuracy of simulation implementation and aids in understanding the effect of model parameters on system performance. Maximising the time satisfaction of ET users and reducing the workload variance of EVCI were the two goals of a multiobjective layout optimisation technique based on the Pareto frontier. The location plans for the new CS based on Pareto analysis can significantly enhance both metrics through simulation evaluation.
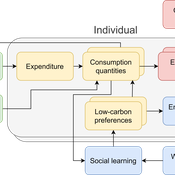
The cultural multiplier of climate policy
Daniel Torren-Peraire | Published Thursday, October 31, 2024For deep decarbonisation, the design of climate policy needs to account for consumption choices being influenced not only by pricing but also by social learning. This involves changes that pertain to the whole spectrum of consumption, possibly involving shifts in lifestyles. In this regard, it is crucial to consider not just short-term social learning processes but also slower, longer-term, cultural change. Against this background, we analyse the interaction between climate policy and cultural change, focusing on carbon taxation. We extend the notion of “social multiplier” of environmental policy derived in an earlier study to the context of multiple consumer needs while allowing for behavioural spillovers between these, giving rise to a “cultural multiplier”. We develop a model to assess how this cultural multiplier contributes to the effectiveness of carbon taxation. Our results show that the cultural multiplier stimulates greater low-carbon consumption compared to fixed preferences. The model results are of particular relevance for policy acceptance due to the cultural multiplier being most effective at low-carbon tax values, relative to a counter-case of short-term social interactions. Notably, at high carbon tax levels, the distinction between social and cultural multiplier effects diminishes, as the strong price signal drives even resistant individuals toward low-carbon consumption. By varying socio-economic conditions, such as substitutability between low- and high-carbon goods, social network structure, proximity of like-minded individuals and the richness of consumption lifestyles, the model provides insight into how cultural change can be leveraged to induce maximum effectiveness of climate policy.
Bargaining with misvaluation
Marcin Czupryna | Published Wednesday, January 14, 2026Subjective biases and errors systematically affect market equilibria, whether at the population level or in bilateral trading. Here, we consider the possibility that an agent engaged in bilateral trading is mistaken about her own valuation of the good she expects to trade, that has not been explicitly incorporated into the existing bilateral trade literature. Although it may sound paradoxical that a subjective private valuation is something an agent can be mistaken about, as it is up to her to fix it, we consider the case in which that agent, seller or buyer, consciously or not, given the structure of a market, a type of good, and a temporary lack of information, may arrive at an erroneous valuation. The typical context through which this possibility may arise is in relation with so-called experience goods, which are sold while all their intrinsic qualities are still unknown (such as untasted bottled fine wines). We model this “private misvaluation” phenomenon in our study. The agents may also be mistaken about how their exchange counterparties are themselves mistaken. Formally, they attribute a certain margin of error to the other agent, which can differ from the actual way that another agent misvalues the good under consideration. This can constitute the source of a second-order misvaluation. We model different attitudes and situations in which agents face unexpected signals from their counterparties and the manner and extent to which they revise their initial beliefs. We analyse and simulate numerically the consequences of first-order and second-order misvaluation on market equilibria.
Agent-based simulation of small group decision-making under no communication
Christopher Poile | Published Thursday, May 26, 2016A computational model of a classic small group study by Alex Bavelas. This computational model was designed to explore the difficulty in translating a seemingly simple real-world experiment into a computational model.
Displaying 10 of 218 results for "Blanca Rosa Cases Gutiérrez" clear search