Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 109 results for "Phesi Project" clear search
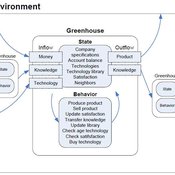
Universal Darwinism in Dutch Greenhouses
Julia Kasmire | Published Wednesday, May 09, 2012 | Last modified Saturday, April 27, 2013An ABM, derived from a case study and a series of surveys with greenhouse growers in the Westland, Netherlands. Experiments using this model showshow that the greenhouse horticulture industry displays diversity, adaptive complexity and an uneven distribution, which all suggest that the industry is an evolving system.
Peer reviewed SIM-VOLATILE: Adoption of emerging circular technologies in the waste-treatment sector
Siavash Farahbakhsh | Published Wednesday, December 14, 2022The SIM-VOLATILE model is a technology adoption model at the population level. The technology, in this model, is called Volatile Fatty Acid Platform (VFAP) and it is in the frame of the circular economy. The technology is considered an emerging technology and it is in the optimization phase. Through the adoption of VFAP, waste-treatment plants will be able to convert organic waste into high-end products rather than focusing on the production of biogas. Moreover, there are three adoption/investment scenarios as the technology enables the production of polyhydroxyalkanoates (PHA), single-cell oils (SCO), and polyunsaturated fatty acids (PUFA). However, due to differences in the processing related to the products, waste-treatment plants need to choose one adoption scenario.
In this simulation, there are several parameters and variables. Agents are heterogeneous waste-treatment plants that face the problem of circular economy technology adoption. Since the technology is emerging, the adoption decision is associated with high risks. In this regard, first, agents evaluate the economic feasibility of the emerging technology for each product (investment scenarios). Second, they will check on the trend of adoption in their social environment (i.e. local pressure for each scenario). Third, they combine these two economic and social assessments with an environmental assessment which is their environmental decision-value (i.e. their status on green technology). This combination gives the agent an overall adaptability fitness value (detailed for each scenario). If this value is above a certain threshold, agents may decide to adopt the emerging technology, which is ultimately depending on their predominant adoption probabilities and market gaps.
An Agent-Based DSS for Word-of-Mouth Programs in Freemium Apps
Manuel Chica | Published Monday, September 05, 2016An agent-based framework that aggregates social network-level individual interactions to run targeting and rewarding programs for a freemium social app. Git source code in https://bitbucket.org/mchserrano/socialdynamicsfreemiumapps

Cultural Evolution of Sustainable Behaviours: Landscape of Affordances Model
Nikita Strelkovskii Roope Oskari Kaaronen | Published Wednesday, December 04, 2019 | Last modified Wednesday, December 04, 2019This NetLogo model illustrates the cultural evolution of pro-environmental behaviour patterns. It illustrates how collective behaviour patterns evolve from interactions between agents and agents (in a social network) as well as agents and the affordances (action opportunities provided by the environment) within a niche. More specifically, the cultural evolution of behaviour patterns is understood in this model as a product of:
- The landscape of affordances provided by the material environment,
- Individual learning and habituation,
- Social learning and network structure,
- Personal states (such as habits and attitudes), and
…
CPNorm
Ruth Meyer | Published Sunday, June 04, 2017 | Last modified Tuesday, June 13, 2017CPNorm is a model of a community of harvesters using a common pool resource where adhering to the optimal extraction level has become a social norm. The model can be used to explore the robustness of norm-driven cooperation in the commons.
An ABM of historic British milk consumption
Matthew Gibson | Published Monday, December 20, 2021Substitution of food products will be key to realising widespread adoption of sustainable diets. We present an agent-based model of decision-making and influences on food choice, and apply it to historically observed trends of British whole and skimmed (including semi) milk consumption from 1974 to 2005. We aim to give a plausible representation of milk choice substitution, and test different mechanisms of choice consideration. Agents are consumers that perceive information regarding the two milk choices, and hold values that inform their position on the health and environmental impact of those choices. Habit, social influence and post-decision evaluation are modelled. Representative survey data on human values and long-running public concerns empirically inform the model. An experiment was run to compare two model variants by how they perform in reproducing these trends. This was measured by recording mean weekly milk consumption per person. The variants differed in how agents became disposed to consider alternative milk choices. One followed a threshold approach, the other was probability based. All other model aspects remained unchanged. An optimisation exercise via an evolutionary algorithm was used to calibrate the model variants independently to observed data. Following calibration, uncertainty and global variance-based temporal sensitivity analysis were conducted. Both model variants were able to reproduce the general pattern of historical milk consumption, however, the probability-based approach gave a closer fit to the observed data, but over a wider range of uncertainty. This responds to, and further highlights, the need for research that looks at, and compares, different models of human decision-making in agent-based and simulation models. This study is the first to present an agent-based modelling of food choice substitution in the context of British milk consumption. It can serve as a valuable pre-curser to the modelling of dietary shift and sustainable product substitution to plant-based alternatives in Britain.

Segregation and Opinion Polarization
Thomas Feliciani Andreas Flache Jochem Tolsma | Published Wednesday, April 13, 2016This is a tool to explore the effects of groups´ spatial segregation on the emergence of opinion polarization. It embeds two opinion formation models: a model of negative (and positive) social influence and a model of persuasive argument exchange.
Agent-Based Model of a Circular Food Packaging Ecosystem to assess Packaging Waste Dynamics
Annoek Reitsema | Published Friday, October 11, 2024Reducing packaging waste is a critical challenge that requires organizations to collaborate within circular ecosystems, considering social, economic, and technical variables like decision-making behavior, material prices, and available technologies. Agent-Based Modeling (ABM) offers a valuable methodology for understanding these complex dynamics. In our research, we have developed an ABM to explore circular ecosystems’ potential in reducing packaging waste, using a case study of the Dutch food packaging ecosystem. The model incorporates three types of agents—beverage producers, packaging producers, and waste treaters—who can form closed-loop recycling systems.
Beverage Producer Agents: These agents represent the beverage company divided into five types based on packaging formats: cans, PET bottles, glass bottles, cartons, and bag-in-boxes. Each producer has specific packaging demands based on product volume, type, weight, and reuse potential. They select packaging suppliers annually, guided by deterministic decision styles: bargaining (seeking the lowest price) or problem-solving (prioritizing high recycled content).
Packaging Producer Agents: These agents are responsible for creating packaging using either recycled or virgin materials. The model assumes a mix of monopolistic and competitive market situations, with agents calculating annual material needs. Decision styles influence their choices: bargaining agents compare recycled and virgin material costs, while problem-solving agents prioritize maximum recycled content. They calculate recycled content in packaging and set prices accordingly, ensuring all produced packaging is sold within or outside the model.
…
Peer reviewed Green Consumption Tipping Point
Mario | Published Thursday, February 26, 2026This model is a minimal agent-based model (ABM) of green consumption and market tipping dynamics in a stylised two-firm economy. It is designed as an existence proof to illustrate how weak individual preferences, when combined with habit formation, social influence, and firm price adaptation, can generate non-linear transitions (tipping points) in market outcomes.
The economy consists of:
1) Two firms, each supplying a differentiated consumption bundle that differs in its fixed green share (one relatively greener, one less green).
2) Many households, each consuming a unit mass per period and allocating consumption between the two firms.
…
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
Displaying 10 of 109 results for "Phesi Project" clear search